Альтернативная реализация декодера VP8 обогнала по производительности код Google
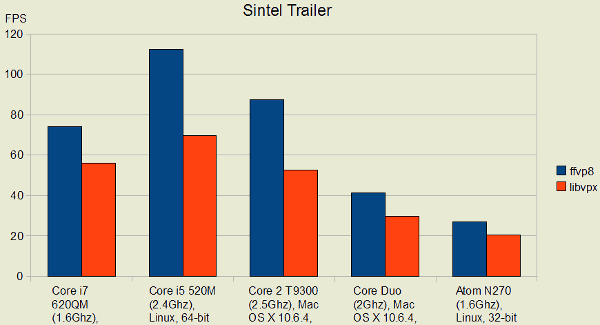
Небольшой отрыв в скорости на процессорах Atom объясняется тем, что разработчики ffvp8 еще не приступили к оптимизации производительности для этого вида процессоров. Несмотря на то, что за месяц после выхода первого рабочего прототипа процесс оптимизации ffvp8 существенно продвинулся вперед, разработка еще остается экспериментальной. Благодаря использованию многих типовых функций, используемых в других декодерах пакета FFmpeg и уже неплохо оптимизированных, код декодера ffvp8 получился достаточно компактным (в пять раз меньше строк кода, чем в эталонном декодере libvpx). Загрузить тестовую версию декодера ffvp8 можно из SVN-репозитория проекта FFmpeg.
В статье также подробно описываются возникшие в процессе работы над ffvp8 проблемы, например, обращается внимание на недостаточно качественное оформление спецификаций, в которых не упомянута логика работы некоторых расширенных функций и некоторые заявления расходятся с практикой, т.е. с тем, что на самом деле представлено в коде. Иными словами, в текущем виде спецификации оказалось недостаточно для создания полностью совместимой с Google реализации декодера, разработчикам пришлось провести серьезный анализ кода, прежде чем удалось добиться полного бинарного совпадения на уровне декодированных потоков.
Из оптимизаций, которые помогли добиться высокой производительности, отмечается проведение работы по увеличению попадания данных в кэш процессора (используется метод умной предварительной загрузки данных из ключевых кадров, обращение к которым наиболее вероятно после обработки текущего кадра) и активное использование ассемблерных оптимизаций с задействованием SIMD-расширений современных процессоров (MMX, SSE, 3DNow), особенно в таких сильно нагружающих CPU задачах, как компенсация движения и фильтр деблокирования. В настоящий момент оптимизация проведена пока только для процессоров x86, поддержка архитектуры ARM остается в планах на будущее.
Также была проведена работа по уменьшению числа распаковки цифровых значений с разной степенью точности (8-битовых в 16-битовые переменные). Например, возьмём операцию abs(a-b) (модуль разности), где a и b - это 8-битные без-знаковые целые числа. Результат вычисления "a - b" требует для своего хранения в памяти 9-бит, так как может быть в промежутке от -255 до 255. Т.е. требуется привлечение дополнительного девятого знакового бита, чего можно избежать используя в условиях конструкцию вида (satsub(a,b) | satsub(b,a)), которая требует всего 4 ассемблерных команд вместо минимум 10 при использовании распаковки.
Источник: http://www.opennet.ru/opennews/art.shtml?num=27425
|
|
0 | Tweet | Нравится |
|



