Открыт код Vespa, движка обработки данных, лежащий в основе многих сайтов Yahoo
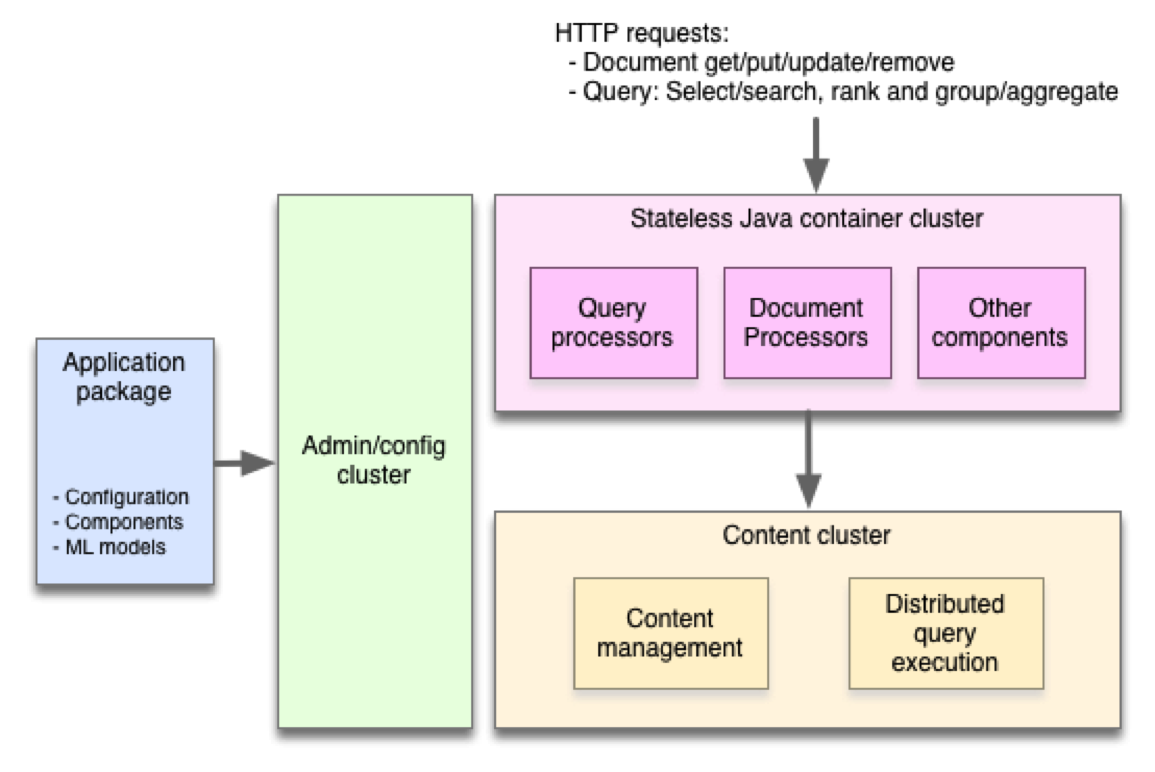
Vespa позволяет c минимальными задержками производить вычисления над большими наборами данных, давая возможность за десятки миллисекунды формировать ответ независимо от размера данных и объёма трафика. Типовыми областями применения Vespa являются приложения для поиска информации, системы персональных рекомендаций, генерируемые в зависимости от предпочтений пользователя навигационные блоки, отображение облаков тегов. Например, во Flickr система Vespa осуществляет обработку ключевых слов и поиск изображений, обрабатывая несколько сотен запросов в секунду к базе из нескольких десятков миллиардов изображений. В рекламной сети Yahoo Gemini решение на базе Vespa выполняет обработку более 3 миллиардов запросов рекламных блоков в день с пиком до 140 тысяч запросов в секунду.
Ключевые возможности Vespa:
- Выборка контента при помощи комбинации из структурированных фильтров на основе SQL-подобных запросов и операций неструктурированного поиска;
- Группировка всех полученных результатов для компоновки итоговых страниц. Все полученные в результате запроса совпадения объединяются в группы и подгруппы, в которых данные агрегируются в наборы, позволяющие реализовать такие возможности, как построение графов связи, облаков тегов, навигационных блоков и т.п.
- Классификация и ранжирование совпадений при помощи моделей релевантности, подготовленных вручную или на основе систем машинного обучения. Каждый элемент подпадающий под запрос ранжируется в соответствии с заданной функцией для дальнейшего использования в таких областях как вычисление релевантности для поиска, формирование рекомендаций, таргетинг и персонализация;
- Обеспечение записи данных для постоянного хранения в режиме реального времени с производительностью на уровне нескольких тысяч записей в секунду на один узел;
- Данные сохраняются в виде документов с произвольной структурой полей, которые могут быть добавлены, заменены, изменены или удалены через простой HTTP API. Документы автоматически реплицируются на несколько узлов в соответствии с заданным в настройках коэффициентом резервирования;
- Поддержка расширения кластера, удаления узлов и переконфигурирования без остановки работы системы;
- Все компоненты Vespa включают средства резервирования и самовосстановления - сбои оборудования обрабатываются на лету и решаются добавлением нового оборудования;
- Отсутствие единой точки отказа, кластер Vespa распределяет данные и вычисления на разные узлы без применения одного управляющего master-сервера;
- Любое приложение для Vespa, независимо от того, будет оно работать на одном узле или в кластере из сотни узлов, оформляется в виде полностью сконфигурированного пакета. Система сама обеспечивает низкоуровневую конфигурацию узлов, процессов и компонентов на основе заданных в пакете правил;
- Система может гибко масштабироваться и запускаться как на одном хосте, так и в кластерах из сотен узлов, обрабатывающих десятки миллиардов документов.
Источник: http://www.opennet.ru/opennews/art.shtml?num=47315
|
|
0 | Tweet | Нравится |
|



