Энтузиасты воссоздали метод мгновенной генерации PDF-файлов с одинаковым хэшем SHA-1
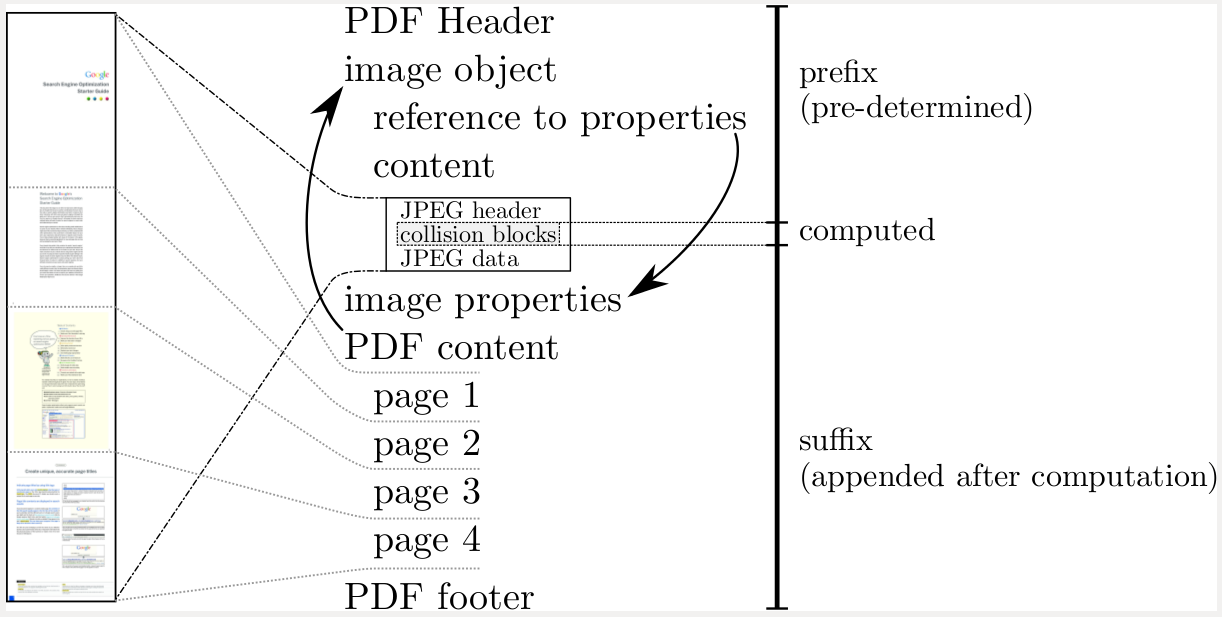
В случае предложенной атаки на PDF, для создания двух PDF-файлов с одинаковыми хэшами SHA-1 больших вычислительных ресурсов не требуется. Суть метода в использовании уже рассчитанной коллизии, позволяющей сохранить хэш SHA-1 при изменении нескольких байт в определённой позиции потока. Для атаки применяются типовые блоки PDF, включающие заголовок PDF, дескриптор потока JPEG и заголовки JPEG. Cодержимое документов для которых нужно создать PDF с одинаковыми хэшами SHA-1 преобразуется в многослойный JPEG, в котором присутствует изображение как первого, так и второго документа.
Наполнение для вызова коллизии включается в состав JPEG. Далее этот общий JPEG прикрепляется к готовым начальным блокам и завершается типовым фиксированным завершающим блоком, содержащим команды отображения PDF. По сути на выходе получаются два почти одинаковые файла, отличающихся только одним параметром в заголовке JPEG, который обеспечивает отображение разных данных в разных PDF-файлах через переключение активного слоя в сводном JPEG-изображении. При открытии первого PDF показывается первый слой, а при открытии другого - второй.
Для разного отображения слоёв применяются манипуляции с заголовками JPEG. В каждом заголовке JPEG имеется поле с комментарием, которое располагается в файле таким образом, чтобы сместить 16-разрядное значение длины поля в область возникновения коллизии. Так как параметр находится в зоне коллизии, его изменение не влияет на вычисленный хэш SHA-1. Манипуляция со значением длины комментария позволяет добиться того, что в первом PDF-файле блок с данными первого изображения попадает в область комментария и отображается второй набор данных, а во втором PDF-файле отображается первый набор данных, а второй игнорируется, так как находится за границей метки конца потока.
Использование типового набора данных для вызова коллизии открывает двери для новых атак, порой неожиданных. Например, разработчики WebKit добавляя в код защиту от вызова коллизии в SHA-1, сами того не желая, обрушили Subversion-зеркало репозитория проекта. Проблема была вызвана тем, что добавив несколько коммитов, содержащих данные, вызывающие коллизию, код дедупликации в SVN-репозитории рассчитал для этих коммитов одинаковый хэш, что нарушило целостность репозитория и заблокировало добавление новых коммитов. Для Git уже вычисленная коллизия не представляет угрозы, но не исключена возможность расчёта новой коллизии, специально для создания конкретного поддельного репозитория Git.
Источник: http://www.opennet.ru/opennews/art.shtml?num=46102
|
|
0 | Tweet | Нравится |
|



