Google открыл код SyntaxNet, системы восприятия естественного языка
Система разработана в рамках проекта, основными задачами которого является придание компьютерным системам возможности читать и понимать человеческий язык. Возможности "Parsey McParseface" и SyntaxNet сравниваются со способностью пятилетнего ребёнка усваивать нюансы языка. Точность работы модели "Parsey McParseface" оценивается Google в 94%. Производительность SyntaxNet позволяет обрабатывать приблизительно 600 слов в секунду на обычном настольном компьютере. В качестве сопутствующих инструментов предоставлены средства для анализа лингвистической структуры предложений или высказываний, показывающие функциональную роль каждого слова.
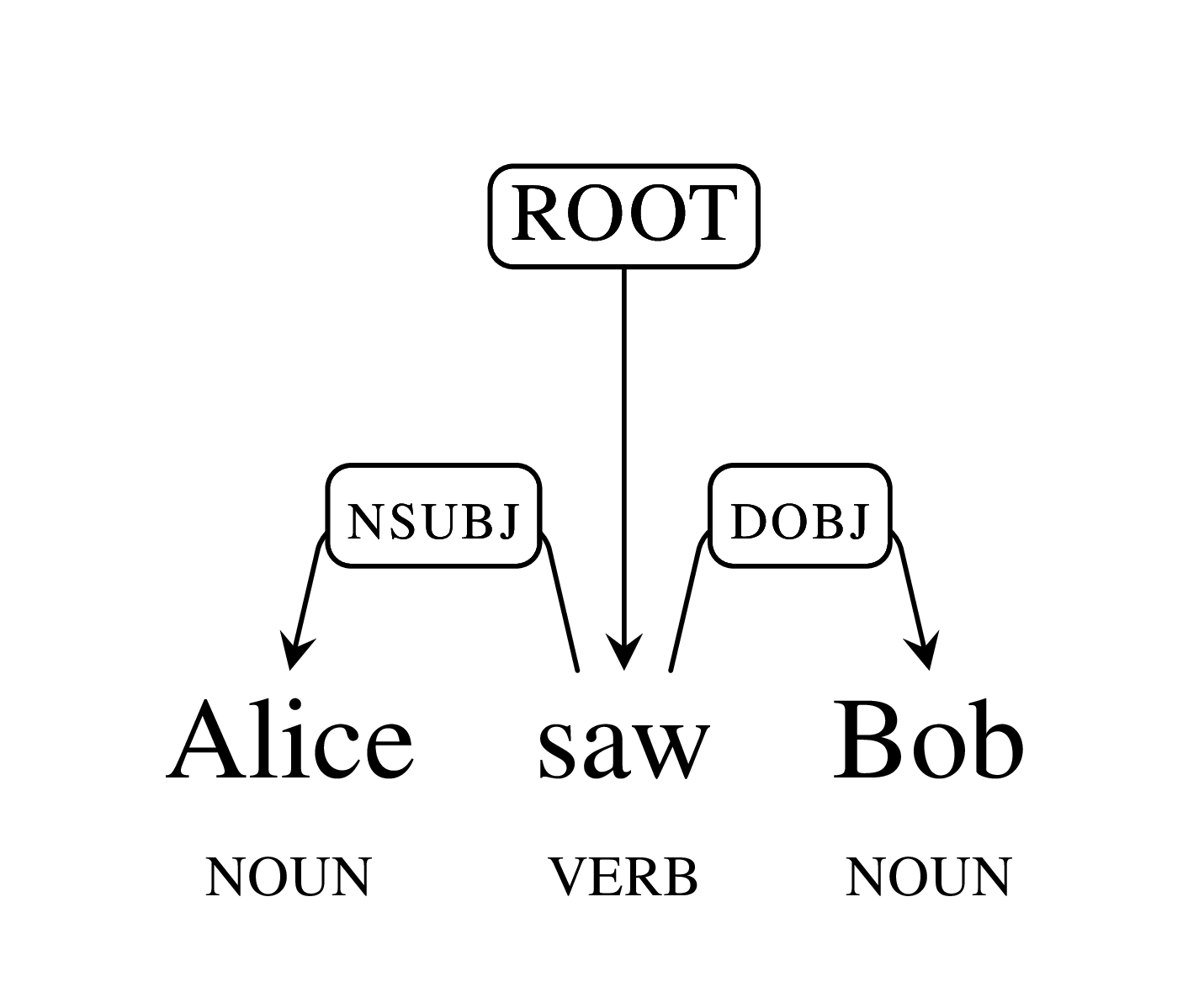
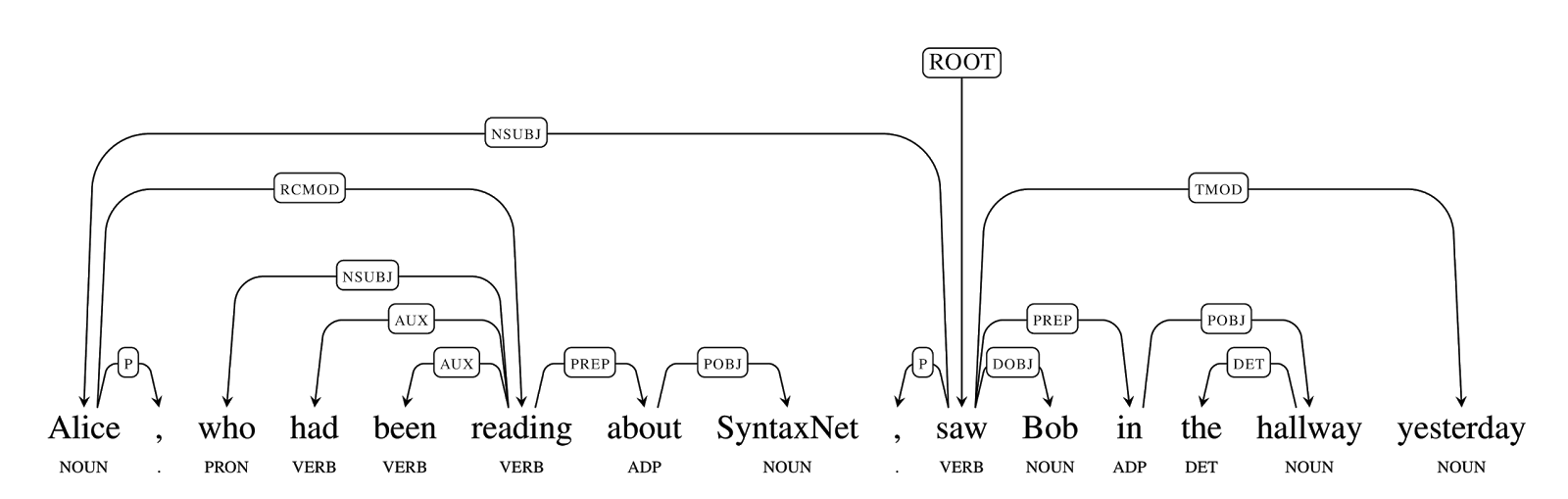
Например, при разборе фразы "Алиса увидела Боба", Алиса и Боб определяются как объекты (существительные), а "увидела" как определяющее действие ключевое слово (глагол). Возможен разбор и более сложных конструкций, например "Алиса, читавшая про SyntaxNet, вчера увидела Боба в прихожей". "Parsey McParseface" и SyntaxNet дают возможность определить зависимости и связи между частями предложения, и ответить на такие вопросы, как кого увидела Алиса, кто увидел Боба, о чём читала Алиса и когда Алиса увидела Боба. При этом сильной стороной SyntaxNet является вовлечение системы машинного обучения, которая позволяет правильно разобрать неоднозначные фразы, воспринимаемые человеком на интуитивном уровне (например, "Я забронировал билет в Google" воспринимается как покупка в Google, а не как билет для доступа в Google).
Источник: http://www.opennet.ru/opennews/art.shtml?num=44416
|
|
0 | Tweet | Нравится |
|



