Microsoft опубликовал на GitHub систему машинного обучения CNTK
CNTK позволяет создавать распределённые нейронные сети, оформленные в виде ориентированного графа, вершины в котором представляют входные значения или параметры нейронной сети, а промежуточные узлы отождествлены с матричными операциями с этими параметрами. CNTK поддерживает различные модели нейронных сетей, включая DNN c прямой связью (feed-forward), свёрточные (CNN) и рекуррентные нейронные сети (RNN/LSTM), а также их комбинации. CNTK ориентирован на использование GPU для вычислений и обеспечивает близкую к линейной масштабируемость при увеличении числа GPU. Поддерживается автоматическое разделение и распараллеливание вычислений с привлечением кластерных конфигураций, включающих большое число GPU.
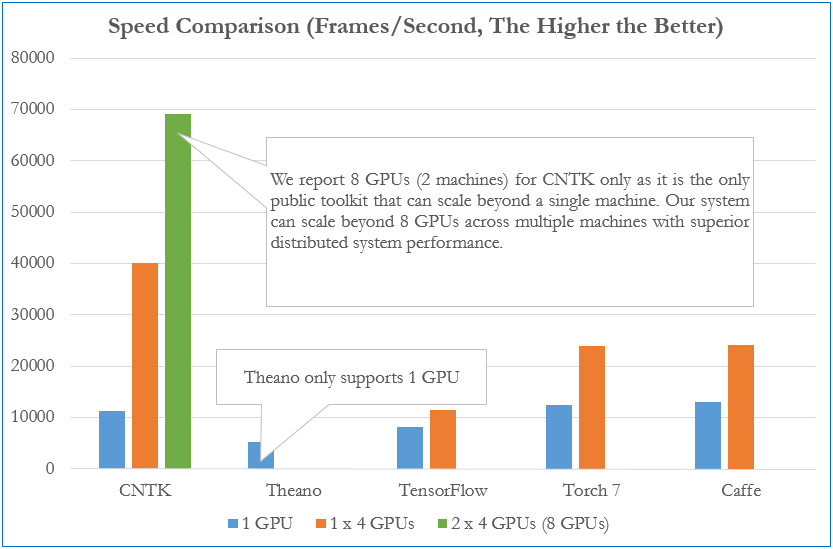
По заявлению Microsoft, CNTK заметно опережает другие аналогичные тулкиты по производительности обработки данных. Например, при развёртывании четырёхуровневой тестовой нейронной сети на Linux-сервере с 4 GPU NVIDIA K40, CNTK быстрее Google TensorFlow в 4 раза, а Torch и Caffe почти в два раза. При задействовании двух аналогичных узлов в Azure GPU Lab (в сумме 8 GPU) производительность CNTK увеличилась на 75%. На системах с одним GPU CNTK немного отстаёт от Torch и Caffe.
Источник: http://www.opennet.ru/opennews/art.shtml?num=43756
|
|
0 | Tweet | Нравится |
|



