AMD развивает основанный на LLVM универсальный компилятор C++ и CUDA для CPU/GPU
Компилятор HCC продолжает развитие ранее представленного компилятора HSA, основанного на наработках проекта LLVM/Clang. В HCC компания AMD попыталась устранить основной барьер, мешающий продвижению развиваемых в AMD технологий гибридных вычислений, - излишнюю усложнённость предложенного решения. HCC даёт разработчикам более высокоуровневые средства разработки, позволяя использовать язык C++, вместо низкоуровневой разработки на Си с применением OpenCL.
В опубликованной на днях спецификации OpenCL 2.1 привязка к языку Си была преодолена благодаря появлению ядра OpenCL C++ и средств для использования расширений для языка C++, но OpenCL всё равно остаётся слишком низкоуровневым API, а также весьма неохотно внедряется в продуктах NVIDIA (NVIDIA ограничивается поддержкой OpenCL 1.2), что приводит к его непопулярности в среде разработчиков высокопроизводительных приложений (в top500 крупнейших кластеров карты NVIDIA используются на 68 системах, а AMD на 3). Компания AMD, которая не отказывается от OpenCL как единого стандарта, в компиляторе HCC попыталась найти разумный выход: разработчик получил возможность применения одного компилятора и одной кодовой базы на языке C++ без выделения в отдельные файлы компонентов, выполняемых на стороне GPU.
Параллелизм достигается благодаря введению расширений HIP (Heterogeneous-compute Interface), которые предлагают два метода разработки. Первый через применение специальных параллельных операций, таких как parallel_for_each, для определения выполняемых параллельно сегментов кода и методов взаимодействия с остальным кодом программы. И второй через использование высокоуровневого API Parallel STL (Standard Template Library), развиваемого в рамках спецификаций C++ 17 и определяющего ряд стандартных функций, выполняемых на стороне GPU.
Для решения проблем с совместимостью AMD разработал инструментарий HIPify для трансляции кода с расширениями CUDA, позволяющий преобразовывать CUDA-проекты в HIP для их последующей компиляции для GPU AMD и, наоборот, транслировать HIP в CUDA для выполнения на GPU NVIDIA. Таким образом удалось добиться полной совместимости с CUDA и предоставить разработчикам возможность использования уже имеющихся CUDA-программ на GPU AMD. При этом AMD поддерживает лишь трансляцию на уровне исходных текстах, не предоставляя средств для выполнения уже скомпилированных CUDA-программ.
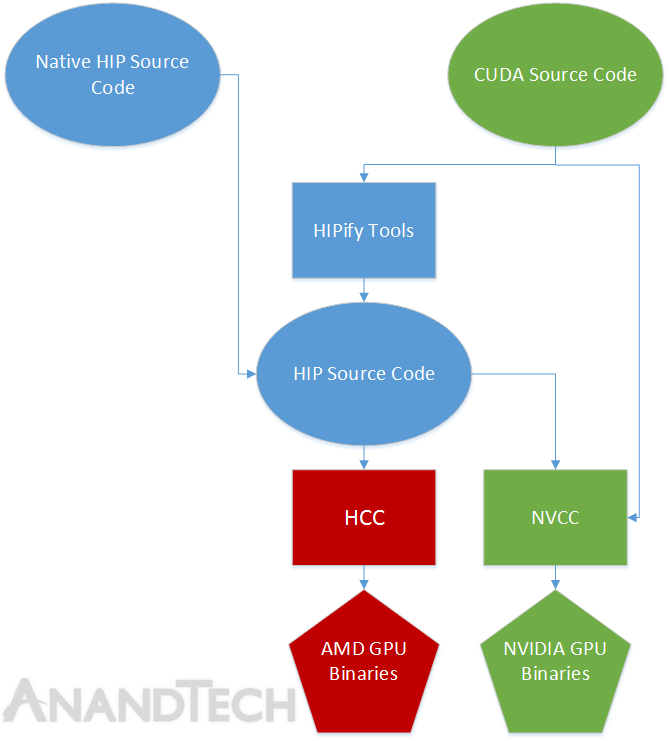
Компания AMD также развивает специализированный 64-разрядный драйвер для Linux, ориентированный на оснащение узлов вычислительных кластеров и запуск приложений в окружении HSA+, примечательном использованием единого для CPU и GPU унифицированного адресного пространства (GPU и CPU могут напрямую обращаться к общим блокам памяти), что существенно упрощает программирование и приближает доступные для GPU AMD средства к возможностям технологии CUDA, используемой компанией NVIDIA. HSA+ дополняет стандартное окружение HSA (Heterogeneous System Architecture) расширениями, обеспечивающими поддержку дискретных GPU (HSA сосредоточен на APU).
Источник: http://www.opennet.ru/opennews/art.shtml?num=43336
|
|
0 | Tweet | Нравится |
|



