LinkedIn открыл код распределённого OLAP-хранилища Pinot
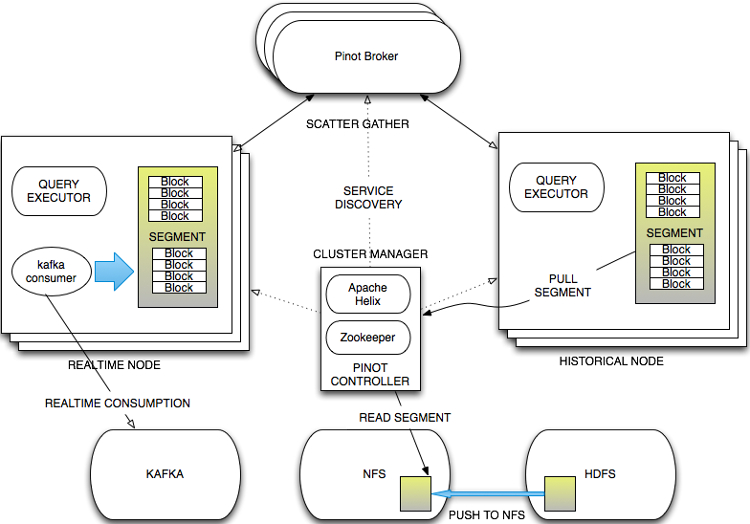
Заявлено обеспечение горизонтальной масштабируемости и возможность хранения огромных объёмов данных. Например, в LinkedIn в Pinot хранится около ста миллирдов записей и ежедневно добавляется более миллиарда новых записей. Ежедневно выполняется около 100 миллионов аналитических запросов, интенсивность которых доходит до тысяч запросов в секунду. Отзывчивость при выполнении запросов составляет около 10 мс. Pinot используется в LinkedIn уже два года и лежит в основе реализации более 25 клиентских и 30 внутренних сервисов, таких как предоставление данных о пользователях посмотревших профиль и сообщение.
В системе предусмотрены средства обеспечения отказоустойчивости и сохранения живучести при возникновении программных и аппаратных ошибок. Pinot подразумевает встраивание репликации и резервного копирования непосредственно в цикл обработки добавляемых в хранилище данных. С одной стороны такой подход позволяет значительно упростить архитектуру, но, с другой стороны, приводит к возникновению секундной задержки между добавлением данных и их доступностью для запросов. Для управления Pinot-кластером применяется Apache Helix.
Обращение к хранилищу производится через привычный SQL-подобный интерфейс, поддерживающий типовые операции фильтрации выборки, агрегирования, сортировки и группировки данных. Для обеспечения предсказуемого времени выполнения запроса не поддерживаются операции слияния таблиц (JOIN). Данные размещаются в таблицах базы данных, ориентированной на столбцы (column-oriented). Поддерживаются различные схемы сжатия и возможность размещения нескольких значений в одном поле. Pinot предоставляет подключаемую систему индексов, в которой можно применять различные технологии индексации.
Источник: http://www.opennet.ru/opennews/art.shtml?num=42415
|
|
0 | Tweet | Нравится |
|



