Выпуск СУБД RethinkDB 2.0
Ключевым отличием RethinkDB от других СУБД является реализация обратной модели доставки результатов запроса. Если традиционная модель "запрос-ответ" требует для отслеживания изменений периодической повторной отправки запросов, то RethinkDB позволяет подписаться на изменения (push-архитектура), т.е. даёт возможность отправить запрос один раз и в live-режиме непрерывно получать информацию об изменении связанных с ним результатов. Подобный подход информирования приложения об изменениях позволяет существенно упростить архитектуру приложений, обрабатывающих данные в режиме реального времени, и уйти от использования внешних очередей сообщений.
Второй важной особенностью RethinkDB является язык запросов ReQL, который интегрируется в объектную модель различных языков программирования. При использовании ReQL запросы формируются в форме обращения к объекту, например, для отслеживания изменений в таблице, в который поле "db" равно "prod", можно выполнить "r.db('rethinkdb').table('stats').filter({ 'db': 'prod' }).changes().run(conn)", а для выборки записей, в которых значение поля "episodes" больше 100 - "r.table('tv_shows').filter(r.row('episodes').gt(100))". ReQL поддерживает создание таблиц (каждая запись может иметь свою структуру), группировку результатов, агрегатные функции, возможность использования в запросах кода на JavaScript и регулярных выражений. Для обработки JavaScript-функций используется движок V8.
Некоторые другие особенности RethinkDB:
- Возможность управления работой СУБД, в том числе анализ статистики и перенос данных между узлами в кластере, через встроенный Web- или CLI-интерфейс.
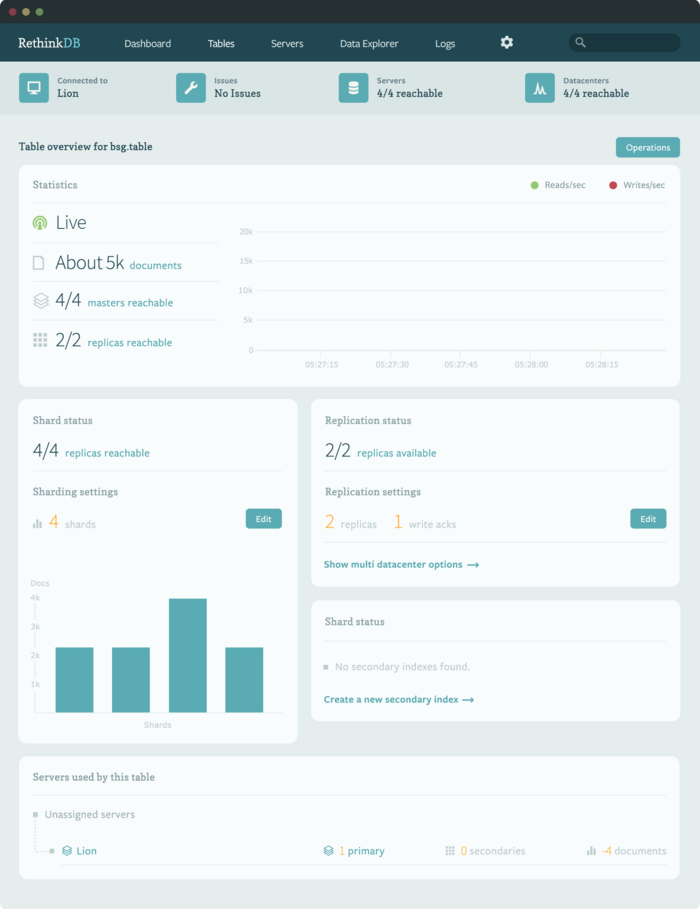
- API для монтиринга за работой СУБД;
- Удобная система настройки репликации на другой сервер или шардинга данных в кластере. Поддержка как асинхронной, так и синхронной репликации;
- Механизм кэширования запросов с произвольной настройкой размера кэша;
- Возможность подсоединения клиента к любому узлу кластера. Все запросы будут автоматически маршрутизированы на нужные узлы. Если запросом охвачены данные на нескольких узлах, то запрос будет разделён на подзапросы к разным серверам, которые будут выполнены параллельно, а затем агрегированы для получения сводного результата;
- Возможность использования механизма map-reduce;
- Размещение данных в B-Tree и хранение с использованием лог-подобных структур, созданных с оглядкой на архитектуру Btrfs. Наличие выполняемого в фоне инкрементального сборщика мусора и упаковщика данных. Гарантирование непротиворечивости данных после сбоя;
- Гибкая система индексов с поддержкой первичных и вторичных ключей, геопространственных индексов, возможностью индексации по произвольным выражениям. Каждый запрос может использовать только один индекс.
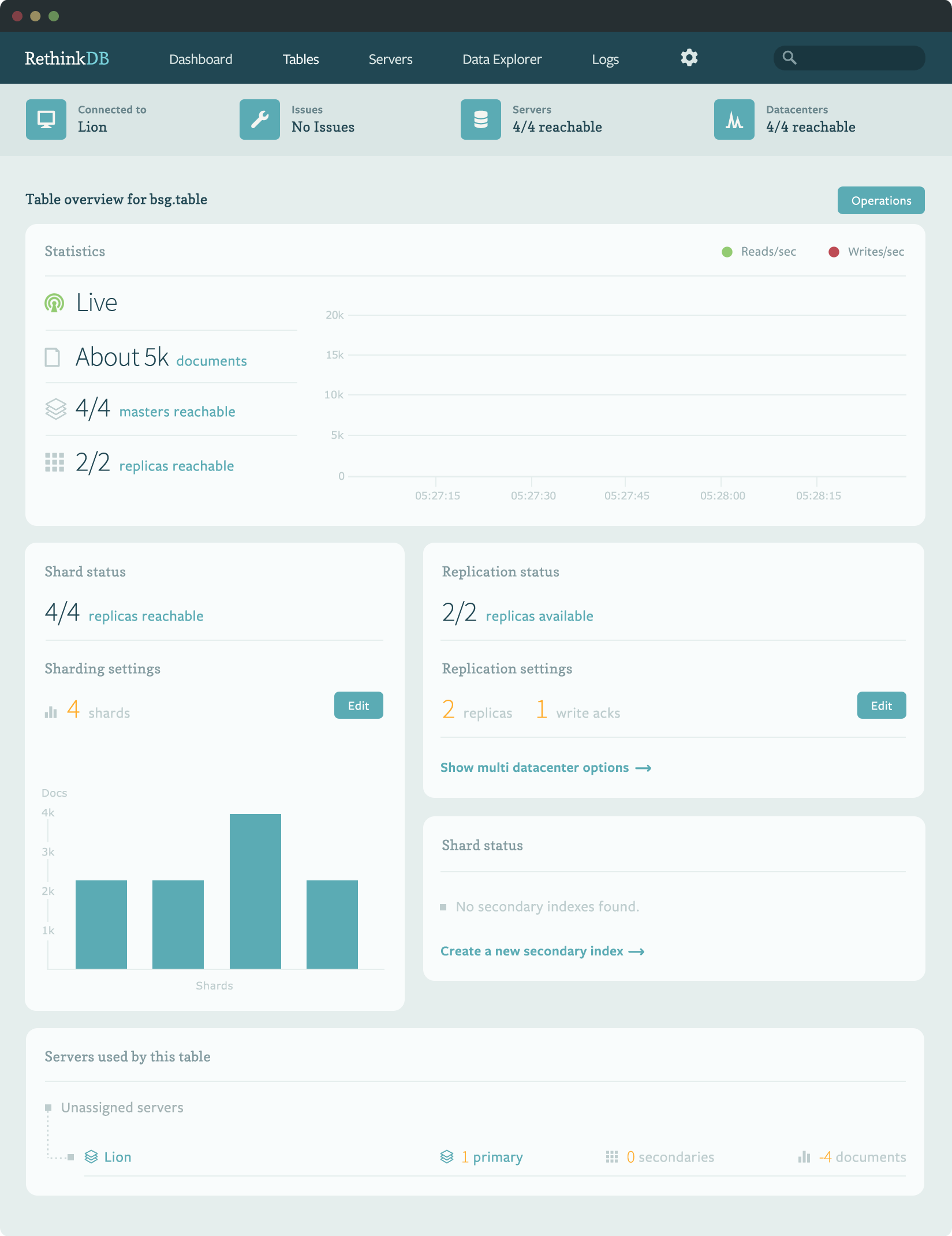
Источник: http://www.opennet.ru/opennews/art.shtml?num=42072
|
|
0 | Tweet | Нравится |
|



