Представлена новая NoSQL БД Hibari, созданная для больших хранилищ данных
API для доступа к данным в Hibari доступно для языков Java, C/C++, Python, Ruby и Erlang. В настоящий момент подготовлены модули эмуляции API Amazon S3, JSON-RPC-RFC4627 и UBP (Universal Binary Protocol), что позволяет использовать БД с типовыми приложениями, написанными для уже существующих стандартных сервисов хранения. В будущем планируется обеспечить поддержу интерфейсов Thrift, Avro и Google Protocol Buffers, а также подготовить прослойку для интеграции с базирующемся на парадигме Map-Reduce проектом Hadoop. Модель данных в Hibari поддерживает пять основных атрибутов: уникальные ключи, сопоставленные с ключами наборы данных, время доступа к данным, срок хранения данных и набор флагов для хранения мета-данных.
Проект Hibari несмотря на первый выпуск имеет стабильную кодовую базу, так как основан на разработках, подготовленных для проприетарной промышленной БД HyperScale Cloud Database. Из достоинств новой БД называется высокая экономическая эффективность (способность работы на обычном недорогом оборудовании), гибкость конфигурации, линейная масштабируемость, высокая производительность, обеспечение гарантированной целостности и непротиворечивости данных, устойчивость к сбоям благодаря дублированию информации на несколько узлов, работа в неблокирующем режиме, автоматическая ребалансировка данных внутри кластера, возможность изменения конфигурации кластера на лету.
В соответствии с CAP-теоремой Эрика Брюэра, распределенное хранилище может соответствовать только двум из трех требований: обеспечение непротиворичивости хранилища в целом, высокая надежность (устойчивость к сбоям) и способность продолжать работу в случае раскола кластера хранения (нарушения связности узлов). БД Hibari удовлетворят первому и второму условию теоремы.
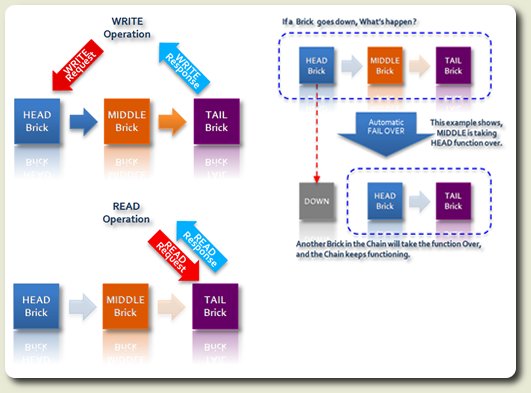
Непротиворечивость данных внутри кластера обеспечивается благодаря использованию технологии репликации цепочек (chain replication), подразумевающей автоматическое последовательное реплицирование блоков данных на три типа узлов внутри "цепочки": голонвой, средний и хвостовой накопитель. Полная согласованность хранимых данных достигается благодаря тому, что все операции записи всегда инициируются только с головного накопителя, а все операции чтения - только с хвостового накопителя. В случае краха узла, другой узел автоматически возьмет на себя нагрузку и роль вышедшего из строя узла (например, в случае сбоя головного накопителя, его место занимает средний, а новый средний формируется в фоне на другом узле кластера).
Источник: http://www.opennet.ru/opennews/art.shtml?num=27481
|
|
0 | Tweet | Нравится |
|



