Компания LexisNexis объявила об открытии системы распределенных вычислений HPCC
Система HPCC написана на языке C++ и конкурирует с написанной на языке Java платформой Hadoop, позволяя, по заявлению LexisNexis, достичь значительно более высокой производительности. В тестовой конфигурации HPCC-кластер из 400 узлов затратил на сортировку 1 Тб данных 102 секунды и выполнил комплексное тестовое задание за 6 минут 27 секунд. То же задание на том же оборудовании Hadoop выполнил за 25 минут 28 секунд, что в 3.95 раз медленнее, чем результат HPCC. Компания Yahoo, используя Hadoop-кластер из 1460 узлов, смогла выполнить сортировку 1 Тб данных за 62 секунды, а 100 Тб на кластере из 3452 узлов за 173 минуты (на сортировку 1 Пб ушло 975 минут).
С точки зрения надежности, решения LexisNexis развиваются уже на протяжении 10 лет и давно используются в промышленном секторе для обработки критически важных данных в таких учреждениях как банки, финансовые компании, правоохранительные органы и правительственные структуры. Система прозрачно масштабируется от одного сервера до кластера из тысяч узлов, при появлении необходимости в расширении хранилища новые узлы могут добавляться на лету. В комплект входят средства для развертывания, мониторинга и управления кластером. Код HPCC в настоящий момент готовится к открытию под лицензией GNU Affero GPL v.3 и будет доступен в течение нескольких недель.
HPCC позволяет хранить и обрабатывать в распределенной кластерной инфраструктуре огромные массивы данных, благодаря массовой параллельной обработке обеспечивая производительность в миллиарды операций в секунду. Например, за доли секунды можно получить доступ, осуществить анализ и произвести изменение выборки из терабайт разрозненных данных, хранимых в разных частях кластера. Для формирования логики выборки данных используется специально разработанный язык манипулирования данными ECL (Enterprise Control Language). Для программирования на языке ECL поставляется специальная интегрированная среда разработки. Итоговый код транслируется в оптимальное представление на языке C++ и может быть собран в виде разделяемой библиотеки. Кроме того, запросы на языке ECL могут быть интегрированы как inline-блоки в программы на языке C++. Поддерживается интеграция ECL и с другими языками программирования. Для ускорения типовых выборок возможно создание индексов по нескольким ключам.
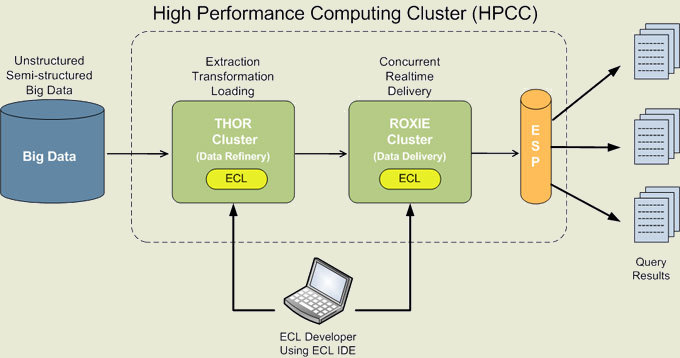
В рамках платформы поддерживаются два механизма обеспечения работы с данными: Roxie (Rapid Online XML Inquiry Engine) - движок для формирования запросов и доставки данных, снабженный элементами для использования в роли warehouse-хранилища, например, поддерживающий выполнение структурированных запросов и аналитических операций; Thor (The Data Refinery Cluster) - похожая по сути на Hadoop MapReduce Cluster распределенная система хранения, объединяющая в единое хранилище информацию с разных узлов кластера и предназначенная для связывания, преобразования и индексации данных.
На конечных узлах данные хранятся в локальной файловой системе Linux. Большие файлы разбиваются на части и хранятся порциями. Возможно подключение специальных трансляторов, которые могут отождествлять файлы с внешними базами, например, с содержимым БД в MySQL. Для обеспечения надежности, данные дублируются на разных узлах, а изменения реплицируются. В случае сбоя, проблемный узел автоматически замещается резервным узлом, а все ранее выполняемые на сбойном узле задания возобновляются с последней контрольной точки. Thor имеет Master/Slave архитектуру, подразумевающую размещение отдельных серверов имен и серверов маппинга размещения файлов на узлах хранения. Roxie оперирует распределенными индексами B+Tree, содержащими информацию о ключах и данных, хранимых в локальных файлах на каждом узле.
Источник: http://www.opennet.ru/opennews/art.shtml?num=30932
|
|
0 | Tweet | Нравится |
|



